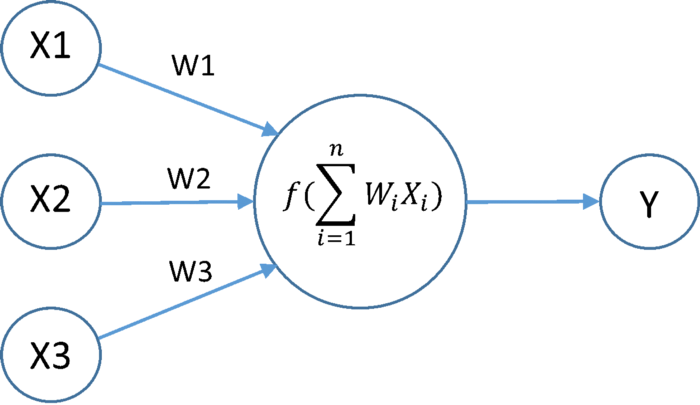
활성화함수 활성화함수는 신경망으로 계산한 입력신호의 모든 합을 각 함수식에 맞게 처리해 출력값으로 변환해주는 역할을 한다. 활성화함수를 사용하는 이유는, 출력값을 비선형의 형태로 바꾸기 위해서이다. 비선형으로 만들어주는 이유는 선형 구조에 문제가 있기 때문이다. 여러개의 선형식 레이어를 아무리 쌓아도 하나의 선형식으로 표현할 수 있기에 비선형 함수를 사용해주어야 한다. 라고 하는데 사실 이해가 완벽하게 되지 않았다. 히든 레이어에서 가중치와 노드값, 편향값들을 어떻게 더하고 곱할지 구성하고 계산하는 것만으로는 비선형식을 만들 수 없는 것일까? 이 부분이 더 궁금해서 찾아보았다. 그리고 그 예측이 맞았다. Geeks for Geeks 라는 해외 사이트에서 활성화함수에 대해 설명한 글을 찾아보았는데, "A ..